Hvordan salgsprognoser blir utført. Prognoser for salg i Excel basert på sesongmessighet
Vi har allerede funnet ut hva en tidsserie og en trendfunksjon er. La oss nå se nærmere på terminologien og fokusere på en av tidsseriemodellene.
Hva en tidsserie består av
Tidsserienivåer (Yt) er summen av to komponenter:
- Vanlig komponent
- Tilfeldig komponent
Til gjengjeld består den vanlige komponenten av:
- Trend
- Sesongmessighet
- Syklisk komponent
Imidlertid trenger ikke modellen å ha alle disse komponentene samtidig.
Den tilfeldige komponenten gjenspeiler innflytelsen fra tilfeldige forstyrrelser på modellen, som hver for seg har ubetydelig innvirkning, men deres totale innvirkning merkes.
Det vil si, generelt sett er tidsserien tilstedeværelsen av fire komponenter:
- Trend (Tt)
- Sesongmessighet (St)
- Syklisitet (Ct)
- Tilfeldige forstyrrelser (Et)
Den sykliske komponenten, i sammenligning med sesongmessigheten, har en lengre effekt og endres fra syklus til syklus. Derfor er det vanligvis kombinert med trenden.
Tidsseriemodelltyper
Vanligvis skilles det mellom to tidsseriemodeller og den tredje blandes.
Når man velger ønsket tidsseriemodell, ser man på amplituden til svingningene i sesongkomponenten. Hvis svingningene er relativt konstante, så velg tilsetningsmodell... Det vil si at svingningens amplitude er omtrent den samme:

Hvis amplituden til sesongmessige svingninger øker eller avtar, bygg multiplikativ modell tidsserie, som setter nivåene i serien avhengig av verdiene til sesongkomponenten.
Konstruksjonen av disse modellene er redusert til å beregne trenden (Tt), sesongmessighet (St) og tilfeldige forstyrrelser (Et) for hvert nivå i serien (Yt).
Modellbyggingsalgoritme
- Vi justerer serien ved hjelp av et glidende gjennomsnitt, det vil si at vi glatter ut serien og filtrerer ut høyfrekvente svingninger.
- Vi beregner verdien av sesongkomponenten St.
- Beregn Tt-verdier ved hjelp av den resulterende trendligningen.
- Ved å bruke de oppnådde verdiene til St og Tt, finner vi de forutsagte verdiene til nivåene i tidsserien.
- Vi vurderer kvaliteten på modellen.
Implementering i praksis
Så vi har tilgjengelige salgsdata for 2016 og 2017, og vi vil forutsi salg for 2018.


Trinn 1
Etter algoritmen vår, må vi glatte ut tidsseriene. La oss bruke metoden for glidende gjennomsnitt. Vi ser at det er store topper hvert år (mai-juni 2016 og april 2017), så la oss ta en bredere utjevningsperiode, for eksempel månedlig dynamikk, dvs. 12 måneder.
Det er mer praktisk å ta utjevningsperioden som et oddetall, deretter formelen for å beregne nivåene i den glattede serien:

yi - den faktiske verdien av det første nivået i serien,
yt er verdien av det glidende gjennomsnittet på tidspunktet t,
2p + 1 - lengden på utjevningsintervallet.
Men siden vi bestemte oss for å bruke den månedlige dynamikken i form av et jevnt tall 12, vil denne formelen ikke fungere for oss, og vi vil bruke denne:
Vi tar med andre ord hensyn til halvparten av ekstreme nivåer av serien i serien, ellers har ikke formelen gjennomgått noen ytterligere endringer. Her er den eksakte formen for vår oppgave:

Utjevner radnivåene våre og strekker formelen ned:

Vi kan umiddelbart lage en graf ut fra de kjente verdiene på salgsnivået og deres glatte. La oss utlede ligningen og verdien av bestemmelseskoeffisienten R ^ 2:

Jeg valgte tredje graders polynom som den glattede, siden den best beskrev nivåene i tidsserien og hadde den største R ^ 2.

Steg 2
Siden vi vurderer en additiv modell av skjemaet:
La oss finne estimatene av sesongkomponenten som forskjellen mellom de faktiske nivåene i serien og verdiene til det glidende gjennomsnittet St + Et \u003d Yt-Tt, siden vi allerede vet Yt og Tt.

Vi bruker estimatene for sesongkomponenten (St + Et) for å beregne verdiene for sesongkomponenten St. For å gjøre dette, la oss finne gjennomsnittlige estimater av sesongkomponenten St. for hvert intervall (over alle år).
Det gjennomsnittlige estimatet av sesongkomponenten er funnet som summen for en kolonne delt på antall fylte rader i den kolonnen. I vårt tilfelle er estimatene for sesongkomponenten plassert i rader uten skjæringspunkt, derfor består summen over kolonnene av enkeltverdier, derfor vil gjennomsnittet være det samme. Hvis vi for eksempel hadde hatt en større periode fra 2015, ville vi ha lagt til en rad til, og vi kunne fullt ut finne gjennomsnittet ved å dele summen med 2.
I modeller med en sesongbestandig komponent antas det vanligvis at sesongmessige tvangsperioder avbrytes. I tilsetningsmodellen kommer dette til uttrykk i at summen av verdiene til sesongkomponenten over alle intervaller skal være lik null. Derfor, etter å ha funnet verdien av den tilfeldige komponenten, dividende summen av gjennomsnittsestimatene for sesongkomponenten med 12, trekker vi verdien fra hvert gjennomsnittsestimat og får den justerte sesongbestanddelen, St.

Trinn 3
Nå beregner vi verdiene til trendnivået T (t) i henhold til ligningen vi fikk da vi bygde den glatte trenden i første trinn.
T (t) \u003d - 23294 + 34114 * t - 1593 * t ^ 2 + 26,3 * t ^ 3
I stedet for t bruker vi verdiene fra kolonnen Periode fra tilsvarende rad.

Trinn 4
Når vi har de beregnede verdiene på S (t) og T (t), kan vi beregne de forutsagte verdiene til nivåene i serien Y (t). For å gjøre dette pålegger vi sesongnivåer på trenden.

La oss nå lage en graf over de kjente verdiene til Y (t) og de som er spådd for 2018.

Så vi fant de anslåtte salgsnivåene for 2018. Verdiene gjenspeiler en oppadgående trend og sesongmessige topper. Disse dataene gir selvfølgelig ikke 100% nøyaktighet, fordi det er mange eksterne påvirkninger som kan endre trendens retning. Derfor bygges det vanligvis et konfidensintervall for de forutsagte verdiene, dette er en korridor der de forutsagte verdiene kan svinge med en gitt sannsynlighet (ofte 95% ). Men jeg snakker om dette i neste artikkel.
Trinn 5
Det gjenstår å evaluere nøyaktigheten til modellen. For å gjøre dette vil vi bruke den gjennomsnittlige tilnærmingsfeilen, som vil bidra til å beregne feilen i relative termer. Med andre ord, dette er gjennomsnittlig avvik for de beregnede verdiene fra de faktiske, som beregnes med formelen:

yi - spådde nivåer av serien,
yi * - faktiske nivåer i serien,
n er antall brettede elementer.

Så vi beregner tilnærmet feil for saken vår. Siden trenden vår er basert på et polynom av tredje grad, begynner de forutsagte verdiene å gjenta de faktiske verdiene godt innen utgangen av 2016, tror jeg, tror jeg, så det ville være mer riktig å beregne tilnærmingsfeilen for 2017-verdiene.

Når vi legger til hele kolonnen med tilnærmingsfeil og deler med 12, får vi den gjennomsnittlige tilnærmingsfeilen 4,13%. Denne verdien er mindre enn 15%, og vi kan konkludere med at modellen er tilstrekkelig.
Husk at prognosene ikke er 100% nøyaktige. Eventuelle uventede ytre påvirkninger kan dreie verdiene til nivåene i serien i en ukjent retning 🙂
Feilen til mange forretningsmenn er blind salg. De lager ingen salgsprognoser, og evaluerer bare resultatene fra rapporteringsperioden. Denne ordningen ligner en berg-og dalbane: nå en topp, så en lang pause.
Hvorfor skulle du ikke gjøre dette?
- Hvis du ikke lager en prognose for salg, faller de ansatte. Det er ingen målestokk for hva du skal tilstrebe.
- Ethvert tall blir evaluert på grunnlag av "i det minste noe".
- Det er ingen konkurranseånd, det er ingen ledere å se opp til.
For å nå mål, må de først settes. For å øke inntektene må du lage en prognose. Det viktigste er at ønsket vekst er realistisk. Praksis viser at prognosetall oppnås når de planlagte indikatorene ikke avviker fra selgernes egentlige evner med ikke mer enn 30-35%.
Vær oppmerksom på følgende metoder for prognoser:
1. Pluss 10% av det som er oppnådd
Denne metoden er kjent for de som har studert den sovjetiske økonomien og dens prognosemetodikk. Hovedpoenget med denne metoden er å forutsi indikatorer 10-15% høyere enn det som ble oppnådd i forrige rapporteringsperiode.
Denne metoden fungerer bra når bedriften din allerede har bygget et salgssystem, og hver leder har minimum akseptable ytelsesindikatorer.
Imidlertid, med denne metoden, er det viktig å etablere de virkelige mulighetene til selgerne dine. Slik at prognosen har en utfordring, og ikke inneholder indikatorer for lavere akseptabelt nivå.
2. Matcher de beste
Det er en populær motivator for å nå dine mål. Hoved essensen av metoden er å vise at hvis noen var i stand til å oppfylle forventningene i salgsprognosen, så kan andre.
Imidlertid, som en guide til tallene i prognosen, er denne metoden ikke alltid effektiv. I det minste, for i enhver salgsavdeling er det "lokomotiver" og "kandidater for oppsigelse." Derfor, for å gjøre prognosen mer realistisk og rettferdiggjort, må du fokusere på noe mellom resultatene fra disse to kategoriene.
3. Vi ser på konkurrentene
Det er logisk å lage en prognose basert på dine egne prestasjoner, men med jevne mellomrom må du sammenligne deg med konkurrentene for å kunne ta en ledende posisjon.
Dette er en fin måte å forutsi salg på hvis du har tilgang til konkurrentinformasjon. Til deres strategi, forretningsprosesser, innkjøpspriser, rabatter og mye mer som ikke er skrevet i kommersielle tilbud og ikke er beskrevet på nettstedet.
Du kan få denne informasjonen på forskjellige måter. Inkludert gjennomføring av partiske arbeidsmetoder. Ring for eksempel en konkurrent forkledd som kunde og se hvordan hans kundeforholdskjede er bygget.
4. Vi oppmuntrer våre ønsker
En av metodene for å lage en prognose for salg er at du starter fra dine virkelige ønsker. Selv om dette ikke samsvarer med sunn fornuft. Men du setter deg bestemte tall for målet ditt og velger metoder for implementeringen.
5. Fokuser på salgstrakten din
Denne metoden kan brukes til prognoser hvis du måler resultatene i alle salgstrinn. De. du kjenner alle tallene som påvirker salget i virksomheten din.
For å få alle nødvendige indikatorer - analyser arbeidet i avdelingen din. For å lage en prognose er det behov for tall for en periode på 2-3 måneder.
Hvilken informasjon bør du analysere:
- hvor mye tid brukes i gjennomsnitt på en kald samtale,
- hvor mye tid som brukes på gjennomsnittlig innsamling av informasjon om en potensiell klient,
- hvor mange samtaler som må ringes for å nå personen, avgjørelse,
- hvor mange møter en leder faktisk kan holde om dagen,
- hvor mange prosent av avtaler som ender med en ordre,
- antall gjentatte salg,
- gjennomsnittlig sjekk.
Med disse tallene i hånden kan du lage en realistisk prognose.
Hvordan dekomponere en plan
Det er nødvendig å bestemme målene du setter i prognosene. Videre er det viktig å dekomponere dem i oppgaver for hver ansatt.
Derfor, når du lager en salgsprognose, kan du dele den totale visjonen inn i bestemte områder du må jobbe med for å oppnå et resultat.
Følgende planer må utarbeides:
- For nye kunder;
- For nye produkter;
- Øke andelen i nåværende kunder;
- Fra forskjellige kanaler;
- Kunden churn;
- Manglende retur av fordringer (hvis det er et slikt problem).
Bryt hver figur i planen i følgende retninger:
- Etter region;
- Etter avdeling;
- Av ansatte;
- Etter måneder / dager;
- Ved mellomliggende ytelsesindikatorer, tatt i betraktning indikatorer for i trakten (nåværende og ny kundebase).
Jo mer nøyaktig og detaljert du deler ned tallene i hver plan, desto mer sannsynlig blir prognosen.
Nedbrytningseksempel
La oss gi et eksempel på nedbrytning av salgsprognosen til nivået på daglige indikatorer for hver ansatt. Men før du gjør dette, må du sørge for at den kommersielle strukturen fungerer optimalt. Det er nødvendig å gjennomføre en liten revisjon på 4 områder.
Kunder. Det er nødvendig å segmentere den nåværende kundebasen for å identifisere hovedmålgruppene og fokusere på å jobbe med de mest lønnsomme.
Kanaler. Analyser konverteringen av hver av dem, ta i betraktning den gjennomsnittlige kostnaden per kundeemne, og slutte å investere i noe som ikke fungerer.
Ansatte. Bare det beste personellet skal være i avdelingen. Screening skjer automatisk hvis du implementerer to prinsipper:
- prinsippet om "sammensatt lønn", der bonusdelen for å oppfylle salgsprognosen er minst 50%;
- prinsippet om "store terskler", som regulerer utbetalingen av bonuser: hvis han ikke oppfylte opptil 80% av planen - mottok han ikke en bonus, 80-100% - pluss 1 lønn, overoppfylt planen - pluss 2 lønn.
Produkter. Bli kvitt illikvide og lavmarginprodukter. Dette vil forhindre ressursforbruk.
Med et optimalt innstilt system, fortsett med nedbrytningen etter planen nedenfor.
1. Bestem det anslåtte fortjenestetallet. Se på fortjenesten fra de foregående periodene. Fjern engangsavtaler. Vurder markedsføringspåvirkning og sesongmessighet.
2. Når du kjenner marginaliteten din, beregner du inntekten etter overskuddsdelen.
3. Del inntektene etter gjennomsnittsregningen og få det omtrentlige antall handler som må lukkes for å oppnå det innstilte overskuddet.
4. Beregn antall potensielle kunder ved hjelp av konverteringsfrekvensen fra applikasjonen til kjøperen.
5. Basert på den mellomliggende konverteringen i trakten, beregne det totale antallet handlinger som må utføres i forretningsprosessen. Vi snakker om samtaler, møter, presentasjoner, returanrop, sendte kommersielle tilbud, fakturaer.
 6. Når du har de kvantitative indikatorene for hvert trinn, kan du dele dem med antall arbeidsdager i prognoseperioden (ofte er det vanlig å snakke om en måned).
6. Når du har de kvantitative indikatorene for hvert trinn, kan du dele dem med antall arbeidsdager i prognoseperioden (ofte er det vanlig å snakke om en måned).
På den måten finner du ut hva hver selger skal gjøre og hvor mye slik at hele avdelingen til slutt vil stenge planen innen utgangen av måneden. Overvåke implementeringen av disse indikatorene på daglig basis.
Hittil har vitenskapen kommet langt i utviklingen av prognoseteknologier. Eksperter er godt klar over metodene for nevrale nettverksprognoser, uklar logikk, etc. De tilsvarende programvarepakkene er utviklet, men i praksis er de dessverre ikke alltid tilgjengelige for den gjennomsnittlige brukeren, og samtidig kan mange av disse problemene løses med hell ved hjelp av metodene for operasjonsforskning, spesielt simuleringsmodellering, spillteori, regresjon og trendanalyse. implementering av disse algoritmene i den velkjente og utbredte programvarepakken MS Excel.
Denne artikkelen presenterer en av de mulige algoritmene for å lage en prognose for salgsvolumet for produkter med sesongbasert salg. Det skal bemerkes med en gang at listen over slike varer er mye bredere enn det ser ut til. Faktum er at begrepet "sesong" i prognoser gjelder alle systematiske svingninger, for eksempel hvis vi snakker om å studere omsetningen i løpet av en uke, betyr begrepet "sesong" en dag. I tillegg kan svingningssyklusen avvike betydelig (både opp og ned) fra verdien på ett år. Og hvis det er mulig å identifisere størrelsen på syklusen til disse svingningene, kan en slik tidsserie brukes til prognoser ved hjelp av additive og multiplikative modeller.
Beregningsmodellen for tilsetningsstoffer kan vises som en formel:
hvor: F - beregnet verdi; T - trend; S - sesongbestanddel E - prognosefeil.
Bruken av multiplikasjonsmodeller skyldes at verdien i sesongkomponenten i noen tidsserier er en viss brøkdel av trendverdien. Disse modellene kan representeres av formelen:
I praksis kan en additivmodell skille seg fra en multiplikativ modell ved størrelsen på sesongvariasjonen. Tilsetningsmodellen har en nesten konstant sesongvariasjon, mens den i multiplikasjonsmodellen øker eller reduseres, grafisk uttrykkes dette i en endring i amplituden til sesongfaktorsvingningen, som vist i figur 1.
Figur: 1. Additive og multiplikative prognosemodeller.
Algoritme for å bygge en prediktiv modell
For å forutsi salgsvolumet, som har sesongmessig karakter, foreslås følgende algoritme for å konstruere en prognosemodell:
1. Trenden bestemmes som best tilnærmer de faktiske dataene. Et viktig poeng her er forslaget om å bruke en polynomtrend, som gjør det mulig å redusere feilen i prognosemodellen.
2. Trekke trendverdiene fra de faktiske salgsvolumene, definere verdiene til sesongkomponenten og justert slik at summen er lik null.
3.Feilene i modellen beregnes som forskjellen mellom de faktiske verdiene og verdiene til modellen .
4. Det bygges en prognosemodell:
hvor:
F - beregnet verdi;
T
- trend;
S
- sesongbestandig komponent;
E -
modellfeil.
5. Basert på modellen bygges den endelige prognosen for salgsvolumet. For dette foreslås det å bruke metoder for eksponentiell utjevning, som gjør det mulig å ta hensyn til mulige fremtidige endringer i økonomiske trender, på grunnlag av hvilke trendmodellen er bygget. Essensen av denne endringen ligger i at den eliminerer mangelen på tilpasningsmodeller, nemlig at den raskt kan ta hensyn til nye økonomiske trender.
F pr t \u003d a F f t-1 + (1-a) F m t
hvor:
F f t-
1 - den faktiske verdien av salgsvolumet året før;
F m t
- verdien av modellen;
og -
glattende konstant
Den praktiske implementeringen av denne metoden avslørte følgende funksjoner:
- for å lage en prognose, må du vite nøyaktig størrelsen på sesongen. Studier viser at mange matvarer er sesongbaserte, og at sesongens størrelse kan variere, fra en uke til ti år eller mer;
- bruken av en polynomtrend i stedet for en lineær kan redusere modellfeilen betydelig;
- hvis det er tilstrekkelig mengde data, gir metoden en god tilnærming og kan effektivt brukes til å forutsi volumet av salg i investeringsdesign.
La oss vurdere anvendelsen av algoritmen i følgende eksempel.
Innledende data: salgsvolum for to sesonger. Som den første informasjonen for prognoser, brukte vi informasjon om salgsvolum av iskrem “Plombir” fra et av selskapene i Nizjnij Novgorod. Denne statistikken er preget av at verdien av salgsvolumet har en uttalt sesongmessig karakter med en økende trend. Den første informasjonen er presentert i tabellen. 1.
Tabell 1.
Faktiske volumer av produktsalg
|
Salgsvolum (rub.) |
Salgsvolum (rub.) |
||||
|
september |
september |
||||
Oppgave: lage en prognose for produktsalg for neste år etter måneder.
La oss implementere algoritmen for å konstruere en prediktiv modell beskrevet ovenfor. Det anbefales å løse dette problemet i MS Excel, noe som vil redusere antall beregninger og tiden for å bygge modellen betydelig.
1. Bestem trendensom best tilnærmer de faktiske dataene. For dette anbefales det å bruke en polynomtrend, som reduserer feilen i prognosemodellen).

Figur: 2. Sammenligningsanalyse av polynom og lineær trend
Figuren viser at polynomtrenden tilnærmer seg de faktiske dataene mye bedre enn den lineære som man vanligvis antydet i litteraturen. Bestemmelseskoeffisienten til polynomtrenden (0,7435) er mye høyere enn den lineære (4E-05). For å beregne trenden, anbefales det å bruke alternativet “Trendline” i PPP Excel.
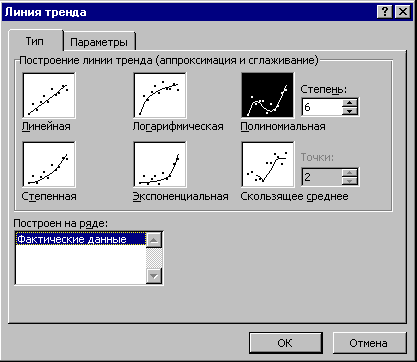
Figur: 3. Alternativ "Trendlinjer"
Bruk av andre typer trend (logaritmisk, kraft, eksponensiell, glidende gjennomsnitt) gir heller ikke et så effektivt resultat. De tilnærmer seg ikke de faktiske verdiene tilfredsstillende, koeffisientene for deres bestemmelse er ubetydelige:
- logaritmisk R2 \u003d 0,0166;
- effekt R2 \u003d 0,0197;
- eksponentiell R2 \u003d 8E-05.
2. Trekke trendverdiene fra de faktiske salgsvolumene , bestemmer vi verdiene til sesongkomponentenved hjelp av MS Excel-applikasjonspakken (fig. 4).

Figur: 4. Beregning av verdiene til sesongkomponenten i PPP MS Excel.
Tabell 2.
Beregner verdiene til sesongkomponenten
|
Måneder |
Volum av salg |
Trendverdi |
Sesongbestanddel |
La oss justere verdiene til sesongkomponenten slik at summen er lik null.
Tabell 3.
Beregning av gjennomsnittsverdiene til sesongkomponenten
|
Måneder |
Sesongbestanddel |
||||
3. Beregn modellfeilene som forskjellen mellom de faktiske verdiene og modellverdiene.
Tabell 4.
Beregning av feil
|
Måned |
Volum av salg |
Modellverdi |
Avvik |
Vi finner rotens gjennomsnittlige kvadratfeil av modellen (E) med formelen:
E \u003d Σ О 2: Σ (T + S) 2
hvor:
T- trendverdien av salgsvolumet;
S
- sesongbestandig komponent;
OM
- avvik fra modellen fra de faktiske verdiene
E \u003d 0,003739 eller 0,37%
Størrelsen på den oppnådde feilen lar oss si at den konstruerte modellen tilnærmer seg de faktiske dataene, dvs. det gjenspeiler fullt ut de økonomiske trendene som bestemmer salgsvolumet, og er en forutsetning for å lage prognoser av høy kvalitet.
La oss lage en prognosemodell:
Den konstruerte modellen er vist grafisk i fig. fem.
5. Basert på modellen bygger vi den endelige prognosen for salgsvolumet. For å redusere innflytelsen fra tidligere trender på påliteligheten til prognosemodellen, foreslås det å kombinere trendanalyse med eksponensiell utjevning. Dette vil gjøre det mulig å utjevne mangelen på adaptive modeller, dvs. ta hensyn til nye økonomiske trender:
F pr t \u003d a F f t-1 + (1-a) F m t
hvor:
F pr t - prognoseverdien av salgsvolumet;
F f t-1
- den faktiske verdien av salgsvolumet året før;
F m t
- verdien av modellen;
og
- utjevningskonstant.
Det anbefales å bestemme utjevningskonstanten ved hjelp av ekspertestimater, som sannsynligheten for å opprettholde den eksisterende markedssituasjonen, dvs. Hvis hovedkarakteristikkene endres / svinger med samme hastighet / amplitude som før, er det ingen forutsetninger for en endring i markedssituasjonen, og derfor er en ® 1, omvendt, så en ® 0.

Figur: 5. Salgsvarselmodell
Dermed blir prognosen for januar i tredje sesong bestemt som følger.
Vi bestemmer den forventede verdien av modellen:
F m t \u003d 1924,92 + 162,44 \u003d 2087 ± 7,8 (rub.)
Faktisk salgsvolum året før (F f t-1)utgjorde 2 361 rubler. Vi aksepterer en utjevningsfaktor på 0,8. La oss få den forventede verdien av salgsvolumet:
F pr t \u003d 0,8 * 2361 + (1-0,8) * 2087 \u003d 2306,2 (rub.)
I tillegg, for å øke påliteligheten av prognosen, anbefales det å bygge alle mulige prognosescenarier og beregne prognosekonfidensintervallet.
Dmitriev Mikhail Nikolaevich, leder av Institutt for økonomi og entreprenørskap ved Nizhny Novgorod University of Architecture and Civil Engineering (NNGASU), doktor i økonomi, professor.
Adresse: 603000, N. Novgorod, st. Gorky, 142a, apt. 25.
Tlf. 37-92-19 (hjemme) 30-54-37 (arbeid)
Koshechkin Sergey Alexandrovich, kandidat for økonomisk vitenskap, kunst. Foreleser ved Institutt for økonomi og entreprenørskap, Nizhny Novgorod University of Architecture and Civil Engineering (NNGASU).
Adresse: 603148, N. Novgorod, st. Chaadaeva, 48, apt. 39.
Tlf. 46-79-20 (hjemme) 30-53-49 (arbeid)
Prognoser er et veldig viktig element i nesten alle aktivitetsfelt, fra økonomi til ingeniørfag. Det er et stort antall programvare som spesialiserer seg på dette området. Dessverre vet ikke alle brukere at en konvensjonell Excel-regnearkprosessor har sine arsenalverktøy for å utføre prognoser, som ikke er dårligere enn effektiviteten til profesjonelle programmer. La oss finne ut hva disse verktøyene er, og hvordan vi kan lage en prognose i praksis.
Formålet med enhver prognose er å identifisere den nåværende trenden og bestemme det forventede resultatet i forhold til objektet som studeres på et bestemt tidspunkt i fremtiden.
Metode 1: trendlinje
En av de mest populære typene grafisk prognoser i Excel er ekstrapolering utført ved å bygge en trendlinje.
La oss prøve å forutsi mengden av selskapets fortjeneste på 3 år basert på data om denne indikatoren for de foregående 12 årene.

Metode 2: PROGNOSE-operatør
Ekstrapolering for tabelldata kan gjøres ved hjelp av standard Excel-funksjonen PROGNOSE... Dette argumentet er kategorisert som et statistisk verktøy og har følgende syntaks:
FORECAST (X, kjent_y, kjent_x)
"X" Er et argument som du vil definere en funksjonsverdi for. I vårt tilfelle vil argumentet være året prognosen skal gjøres for.
"Kjente y-verdier" - basen av kjente verdier for funksjonen. I vårt tilfelle spilles dens rolle av gevinsten for tidligere perioder.
"Kjente x-verdier" Er argumentene som tilsvarer de kjente verdiene til funksjonen. I deres rolle har vi nummereringen av årene informasjonen om fortjenesten fra de foregående årene ble samlet inn for.
Argumentet trenger naturligvis ikke å være en tidsperiode. For eksempel kan det være temperatur, og verdien av funksjonen kan være ekspansjonsnivået for vann når det varmes opp.
Ved beregning av denne metoden brukes den lineære regresjonsmetoden.
La oss se på nyansene ved å bruke operatøren PROGNOSE med et spesifikt eksempel. La oss ta hele samme bord. Vi må vite resultatprognosen for 2018.


Men ikke glem at, som i konstruksjonen av en trendlinje, skal tidsperioden før prognoseperioden ikke overstige 30% av hele perioden databasen ble akkumulert for.
Metode 3: TREND-operatøren
En funksjon til kan brukes til prognoser - TREND... Det tilhører også kategorien statistiske operatører. Syntaksen er veldig lik den for et verktøy PROGNOSE og ser slik ut:
TREND (Kjent_y; kjent_x; ny_x; [const])
Som du kan se, argumentene "Kjente y-verdier" og "Kjente x-verdier" samsvarer fullt ut med lignende elementer fra operatøren PROGNOSEog argumentet "Nye x-verdier" samsvarer med argumentet "X" forrige verktøy. Videre i TREND det er et ekstra argument "Konstant", men det er valgfritt og brukes bare når konstante faktorer er til stede.
Denne operatøren brukes mest effektivt i nærvær av en avhengighet av lineær funksjon.
La oss se hvordan dette verktøyet vil fungere med samme datasett. For å sammenligne de oppnådde resultatene, vil vi definere 2019 som prognosepunkt.


Metode 4: operatør VEKST
En annen funksjon som du kan lage prognoser i Excel er GROWTH-operatøren. Den tilhører også den statistiske gruppen av verktøy, men i motsetning til de forrige bruker den ikke en lineær avhengighetsmetode, men en eksponentiell. Syntaksen for dette verktøyet ser slik ut:
VEKST (kjent_y; kjent_x; ny_x; [const])
Som du kan se, gjentar argumentene til denne funksjonen nøyaktig operatørens argumenter TREND, så vi vil ikke dvele ved beskrivelsen deres for andre gang, men vi vil umiddelbart gå videre til å bruke dette verktøyet i praksis.


Metode 5: LINEST-operatøren
Operatør LINEST bruker metoden for lineær tilnærming ved beregning. Det skal ikke forveksles med den lineære avhengighetsmetoden som brukes av verktøyet. TREND... Syntaksen ser slik ut:
LINEST (Kjent_y; kjent_x; ny_x; [const]; [statistikk])
De to siste argumentene er valgfrie. Vi er kjent med de to første fra de tidligere metodene. Men du har sannsynligvis lagt merke til at denne funksjonen mangler et argument for å peke på de nye verdiene. Faktum er at dette verktøyet bare bestemmer endringen i inntektsmengden per enhet i perioden, som i vårt tilfelle er lik ett år, men vi må beregne totalsummen separat, og legge resultatet av operatørens beregning til den siste faktiske verdien av fortjenesten LINESTganget med antall år.


Som du kan se, vil den forventede profittverdien, beregnet av den lineære tilnærmingsmetoden, i 2019 utgjøre 4614,9 tusen rubler.
Metode 6: operatør LGRFPRIBL
Det siste verktøyet vi skal se på vil være LGRFPRIBL... Denne operatøren utfører beregninger basert på den eksponentielle tilnærmingsmetoden. Syntaksen er strukturert som følger:
LGRFPRIBL (kjent_y; kjent_x; new_x;; [const]; [statistikk])
Som du kan se, gjentar alle argumentene de tilsvarende elementene i den forrige funksjonen fullstendig. Prognoseberegningsalgoritmen vil endres noe. Funksjonen vil beregne en eksponentiell trend som vil vise hvor mange ganger inntektene vil endres over en periode, det vil si i et år. Vi må finne forskjellen i fortjeneste mellom siste faktiske periode og første planlagte periode, multiplisere den med antall planlagte perioder (3) og legg til resultatet summen av den siste faktiske perioden.


Det forventede overskuddsmengden i 2019, som ble beregnet ved hjelp av den eksponentielle tilnærmingsmetoden, vil utgjøre 4639,2 tusen rubler, som igjen ikke skiller seg mye fra resultatene oppnådd ved beregning av de tidligere metodene.
Vi fant ut på hvilke måter du kan lage prognoser i Excel. Grafisk kan dette gjøres ved bruk av en trendlinje, og analytisk - ved hjelp av en rekke innebygde statistiske funksjoner. Behandlingen av identiske data fra disse operatørene kan føre til forskjellige resultater. Men dette er ikke overraskende, siden de alle bruker forskjellige beregningsmetoder. Hvis svingningen er liten, kan alle disse alternativene, som gjelder for et bestemt tilfelle, betraktes som relativt pålitelige.
Denne artikkelen viser deg hvordan du beregner i Excel salgsprognose med tanke på vekst og sesongmessighet.
Ved å forutsi salg på denne måten vil du få det mest nøyaktige og lydvarsel i lang tid.
Prosess beregning av prognosen delt inn i 3 deler:
- Beregning av trendverdi;
- Definisjon sesongfaktorer;
- Salgsvarsling;
La oss beregne prognosen etter måneder i 2 år og 3 måneder basert på salg i 5 år (se vedlagt fil).
Slik beregner du trendverdier:
Du kan lese om forskjellige alternativer for beregning av lineære trendverdier i artikkelen "" og velge den mest praktiske for deg selv.
For å beregne sesongfaktorer:
- Vi beregner avviket fra de faktiske verdiene fra trendverdiene. For dette deles de faktiske verdiene av trendverdiene;
- For hver måned bestemmer vi gjennomsnittlig avvik de siste 5 årene.
- Vi bestemmer den generelle sesongindeksen - gjennomsnittsverdien av koeffisientene beregnet i avsnitt 4;
- Vi beregner sesongkoeffisientene; hver koeffisient fra punkt 4 er delt av koeffisienten fra punkt 5 (se vedlagt fil);
Vi beregner salgsprognosen med tanke på vekst og sesongmessighet:
- Vi setter perioden vi vil beregne prognosen for. For å gjøre dette utvider vi antall tidsserieperioder med 2 år og 3 måneder.
- Vi teller tren-verdier for fremtidige perioder... Vi erstatter de beregnede trendkoeffisientene b og a i ligningen y \u003d bx + a, x er tallet for perioden i tidsserien (fra 61 til 87). Vi får y-verdiene til den lineære trenden for hver fremtidig periode (se vedlagt fil).
- Vi beregner prognosen... For dette multipliseres verdiene til den lineære trenden med sesongfaktorene.
Prognosen, med tanke på vekst og sesongmessighet, er klar.
For mer nøyaktig salgsvarsling det er ikke nok å ta hensyn til vekst og sesongmessighet, det er også nødvendig å ta hensyn til ytterligere faktorer som påvirker salget betydelig, som f.eks.
salgsfremmende aktiviteter,
innføring av nye produkter,
åpning av nye salgsområder,
spesialist. kunder med engangsbetydelige kjøp
osv., men mer om det i de neste artiklene.
Nøyaktige spådommer for deg!
Bruke programmet Prognose4AC PRO vil du kunne beregne vekst- og sesongvarighetsprognosen for mer enn 5000 linjer samtidig med ett tastetrykk. Enkelt og raskt!
Bli med oss!
Last ned gratis apper for prognoser og forretningsanalyse:
- Novo Prognose Lite - Automatisk prognoseberegning i utmerke.
- 4analytics - ABC-XYZ analyse og analyse av utslipp i Utmerke.
- Qlik Sense Desktop og QlikViewPersonal Edition - BI-systemer for dataanalyse og visualisering.
Test evnen til betalte løsninger:
- Novo Prognose PRO - prognoser i Excel for store datasett.

 Slik markedsfører du et produkt riktig: markedsføringsaktiviteter
Slik markedsfører du et produkt riktig: markedsføringsaktiviteter Metoder og måter å vurdere effektiviteten av reklame på
Metoder og måter å vurdere effektiviteten av reklame på Metoder for å fremme salg av varer
Metoder for å fremme salg av varer Hva er inngående markedsføring?
Hva er inngående markedsføring?